
A era da informação poderá entrar em outro nível de acesso ao conhecimento com Sistemas de Pesquisa Abrangente.
Bem-viiindos! É percepção minha ou cada vez mais se fala de novas soluções de inteligência artificial baseadas em modelos de linguagem (LLM)? Ou que usam modelo de linguagem como seu motor de desambiguação?
Me parece que, a cada novo anúncio, os modelos de linguagem passam a compor soluções, sendo parte de um sistema que se propõe a atender uma finalidade autônoma, ao menos à primeira vista, pois rapidamente é tratado como um serviço, se tornando parte de uma solução maior.
E é com este contexto que irei abordar, o que estou chamando de “3ª Geração: IA Mineradora”, como mais uma evolução na Era da IA.
Em 02/Fev/2025 a OpenAI lançou o Deep Research, uma solução composta por IA agentica e pelo modelo o3 (reasoning capability model).
O que é o Deep Research?
Segundo a própria OpenAI, trata-se de:
- Um agente que usa o raciocínio para sintetizar grandes quantidades de informações on-line e concluir tarefas de pesquisa em várias etapas.
Falando com outras palavras, pense em um super buscador onde portais, artigos, documentos e tudo mais que estiver acessível na internet será vasculhado e interpretado com abrangência e guiado por um modelo com capacidade de “raciocínio”, que questiona as respostas obtidas, continuando a pesquisar, durante dezenas de minutos, até alcançar um resultado robusto e contextualizado o suficiente para atender as expectativas de entrega!
Um Novo Paradigma de Pesquisa Abrangente
Dias após o lançamento da OpenAI, o Hugging Face fez sua contribuição com um estudo e proposta de solução open-source com o artigo Open-source DeepResearch – Freeing our search agents.
Com base em novas abordagens, pesquisas que combinam de maneira inteligente a consulta a internet e documentos locais, permitindo a geração de resultados de pesquisa detalhados e em busca de dados factuais e imparciais, permitiu vislumbrar o potencial que esse conceito pode trazer.
Estudando o que foi apresentado pela Hugging Face, fui em busca de soluções open-source no github. Após algumas pesquisas, avaliações e testes, escolhi duas soluções e as trouxe para servir como base de explicação e aplicação do conceito:
- o GPT Researcher: agente autônomo projetado para pesquisa abrangente na internet e infraestrutura local.
- o Smolagents: biblioteca que permite executar agentes poderosos com suporte a entradas de texto, visão, vídeo e até áudio! Suportando qualquer LLM, podendo ser um modelo SaaS ou infraestrutura local.
Esse novo paradigma tem inspiração em metodologias como as apresentadas nos artigos Plan-and-Solve Prompting e RAG (Retrieval-Augmented Generation), que podem mudar a forma de se realizar pesquisas complexas. Aspectos como o combate à desinformação, velocidade de resposta e confiabilidade, são parte dos passos para automatizar esse fluxo.
A Integração Multimodal:
Esse sistema de pesquisa abrangente integra duas frentes:
- a recuperação de informações, que abrange a busca e indexação de documentos na internet e bases locais;
- a geração de conteúdo a partir desses dados.
Essa integração permite que o pesquisador – ou o próprio sistema automatizado – produza um relatório que responde a uma consulta de forma detalhada, apresentando referências diretas aos documentos encontrados, que possa fortalecer a veracidade, transparência da informação e linhagem do conhecimento derivado.
Uma das inovações é a capacidade de inserir automaticamente citações (com formatação padronizada) no texto gerado ou derivado. Isso garante que cada afirmação ou dado apresentado tenha uma fonte de respaldo, o que é importante para combater a desinformação e manter a integridade das informações entregues.
Métodos e Inspiração: Plan-and-Solve e RAG
Plan-and-Solve Prompting:
O framework Plan-and-Solve Prompting propõe uma divisão clara entre a fase de planejamento e a de resolução. Na etapa de planejamento, o framework elabora um “mapa” do problema, identificando as áreas de conhecimento necessárias, definindo os tópicos e a estrutura do resultado. Esse plano serve como guia para a etapa de solução, onde a extração e a síntese de informações são realizadas de forma direcionada e ordenada.
A estruturação lógica se dá ao definir previamente os tópicos, o framework evita saltos ou omissões na obtenção de dados e informações, garantindo que o resultado seja coeso e abrangente.
O foco na relevância permite priorizar fontes confiáveis e dados que realmente respondem à pergunta de pesquisa, minimizando o risco de incluir informações equivocadas.
Retrieval-Augmented Generation (RAG):
Essa abordagem combina modelos de linguagem com um mecanismo de recuperação de informações. Em vez de depender exclusivamente do conhecimento interno do modelo (que pode estar defasado ou incompleto), o RAG armazena e torna acessíveis bases de conhecimento – da internet e repositórios locais – para reunir conteúdo de contexto considerando o tema em pesquisa e dados atualizados e verificados.
Fluxo de Interação para Operação:
A partir de uma pergunta ou tema, o framework dispara buscas em múltiplas fontes para recuperação de conteúdo a partir de documentos e trechos relevantes que podem ser recuperados com base na pertinência e confiabilidade da fonte. Onde o modelo integra com essas informações, gerando um texto coeso e embutindo as devidas citações.
A consulta em tempo real permite que o resultado reflita o estado mais recente do conhecimento e ao ancorar a geração em dados reais, o RAG contribui para que o conteúdo produzido seja menos suscetível a erros factuais, possibilitando redução de alucinações.
Automatizando a Abordagem: Primeiros Passos
Para implementar uma solução que combine esses métodos e atenda aos critérios de cuidado com a desinformação, velocidade de processamento, entrega e confiabilidade dos resultados, os primeiros passos incluem:
- Desenvolvimento de um módulo de recuperação de dados:
- Criar pipelines que indexem as informações da internet e bases de dados locais;
- Utilizar técnicas de ranking (p.e., BM25 ou embeddings semânticos) para priorizar documentos confiáveis.
- Fase de planejamento (Plan-and-Solve Prompting):
- Desenvolver algoritmos que, a partir da consulta, elaborem um esboço estruturado do resultado, definindo os tópicos principais e as seções necessárias;
- Estabelecer parâmetros para que apenas fontes com alta confiabilidade baseadas em métricas de autoria, data de publicação e consenso acadêmico, sejam selecionadas.
- Integração com modelos de linguagem e RAG:
- Conectar o módulo de recuperação a um modelo de geração que utiliza o esboço como guia, garantindo que o texto produzido incorpore os dados recuperados com as citações correspondentes;
- Implementar mecanismos de fact-checking (p.e., cruzamento de dados entre múltiplas fontes) para validar as informações antes da inserção no resultado.
- Automatização e monitoramento:
- Estabelecer um sistema de feedback que permita corrigir possíveis erros e ajustar os critérios de relevância, aumentando o determinismo do sistema, garantindo que os mesmos inputs produzam resultados consistentes;
- Otimizar os processos para que a recuperação e a síntese ocorram em tempo quase real, sem sacrificar a qualidade das informações.
- Interface de usuário e transparência:
- Desenvolver uma interface que permita ao usuário ver, a qualquer momento, as fontes originais das informações apresentadas, reforçando a confiabilidade do relatório;
- Manter registros, com log de processo, dos passos de recuperação e síntese para auditoria e para aprimoramento contínuo do sistema.
Evitar Desinformação e Zelar pela Confiabilidade
Uma abordagem automatizada busca reduzir o risco de desinformação ao envolver fontes verificadas e de mecanismos de fact-checking integrados. A inclusão de citações diretas permite que o usuário leitor verifique a veracidade dos dados.
Ao separar claramente a etapa de planejamento da etapa de solução, e ao utilizar algoritmos padronizados para recuperação e síntese, o sistema se torna mais determinístico, ou seja, oferecer resultados reprodutíveis para as mesmas consultas, aumentando a confiança no processo.
A utilização de arquiteturas baseadas em RAG permite que o sistema seja eficiente, respondendo rapidamente às consultas sem comprometer a qualidade das informações. Essa performance é essencial em contextos em que a atualização constante dos dados é fundamental.
Exemplos de Aplicação no Mundo Real
- Pesquisa Acadêmica: Universidades e centros de pesquisa podem automatizar a elaboração de revisões de literatura, integrando artigos acadêmicos e dados de repositórios locais com notícias e resultados de pesquisas recentes da internet.
- Monitoramento de Desinformação: Agências de fact-checking e órgãos governamentais podem utilizar esse sistema para monitorar e apoiar a desmentir informações falsas que circulam na internet, apresentando resultados detalhados, com referências acessíveis e indexadas.
- Inteligência Competitiva: Empresas que precisam acompanhar tendências do mercado podem gerar relatórios detalhados com base em muitas fontes de informação, garantindo que os dados estejam sempre atualizados e fundamentados.
- Inovação disruptiva: Por se tratar de um processo de transformação de um produto, serviço ou tecnologia, que pode substituir ou melhorar a versão atual, a inovação disruptiva pode ser potencializada com pesquisas de mercado, estudo de benchmarks no setor de atuação e reavaliar processos com potencial de transformação.
Partindo para a Prática Open-Source
Para a solução GPT Researcher, rodando localmente a partir de um git clone no VSCode, executei os comandos:
- pip install -r requirements.txt
- python -m uvicorn main:app –reload
Com isso, o front-end abaixo foi apresentado:
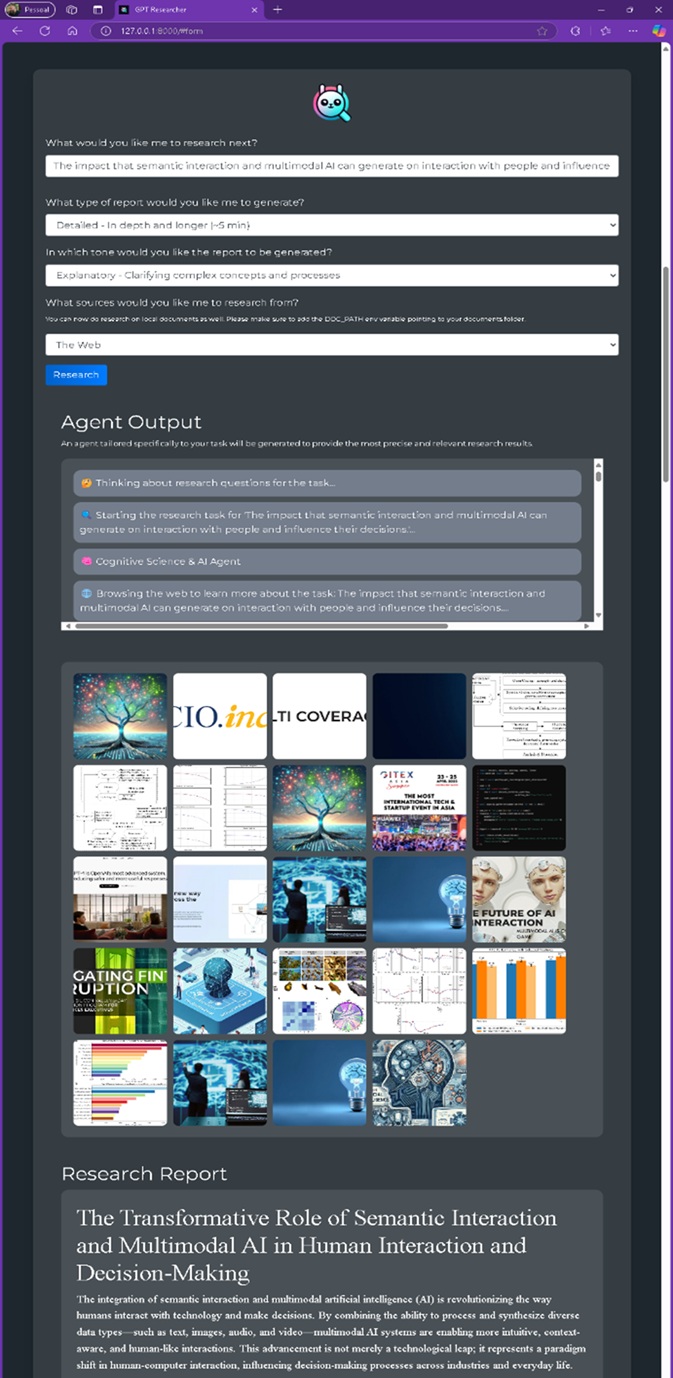
Figura 1: Front-end de interação, utilizando a sentença “The impact that semantic interaction and multimodal AI can generate on interaction with people and influence their decisions” para execução do Sistema de Pesquisa Abrangente, resultado no “Research Report”.
Para a solução Smolagents, rodando localmente a partir de um git clone no VSCode, executei o comando pip install smolagents no terminal, posteriormente abri uma sessão do de Jupyter Notebook, conforme abaixo:
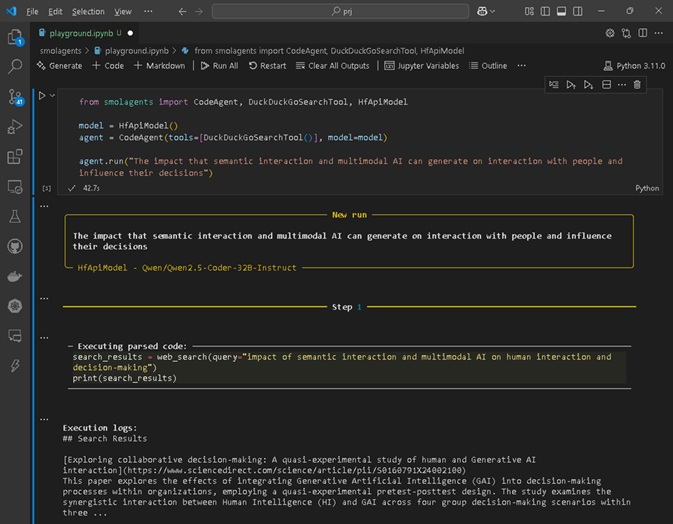
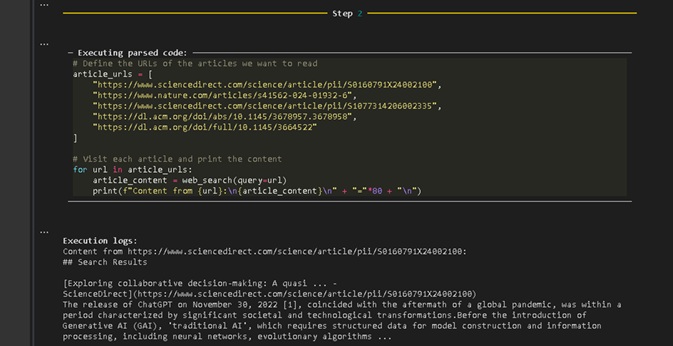
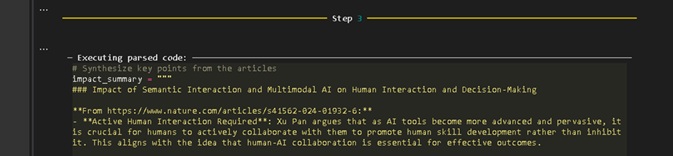
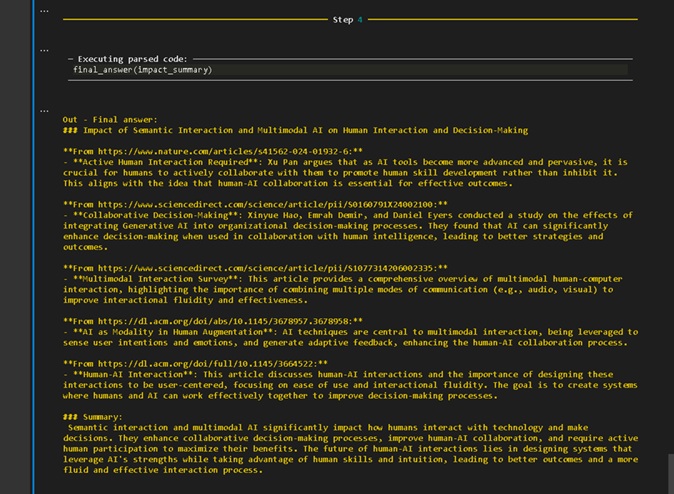
Figura 2: Sessão Jupyter Notebook para interação, utilizando a sentença “The impact that semantic interaction and multimodal AI can generate on interaction with people and influence their decisions” para execução do Sistema de Pesquisa Abrangente, resultado no “Step 4”.
Ambas as soluções fizeram seu trabalho: investiram tempo na profundidade de pesquisa na internet, ajudado por modelos de linguagem, 4o e llama3.2:3b, respectivamente.
A solução GPT Research ajudou a estruturar os parâmetros de pesquisa, solicitando:
- “O que você gostaria que eu pesquisasse a seguir?”
- “Que tipo de relatório você gostaria que eu fizesse gerar?”
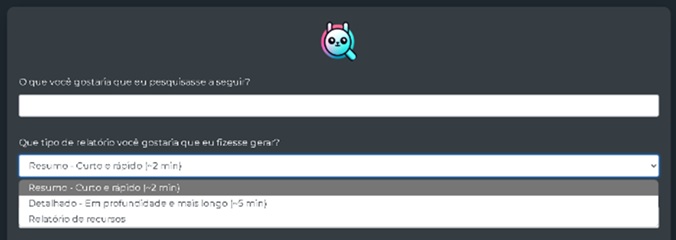
Figura 3: Front-end de interação do GPT Research, com o combobox aberto para escolha do tipo de relatório, exibindo suas opções.
- “Em que tom gostaria que o relatório fosse gerado?”
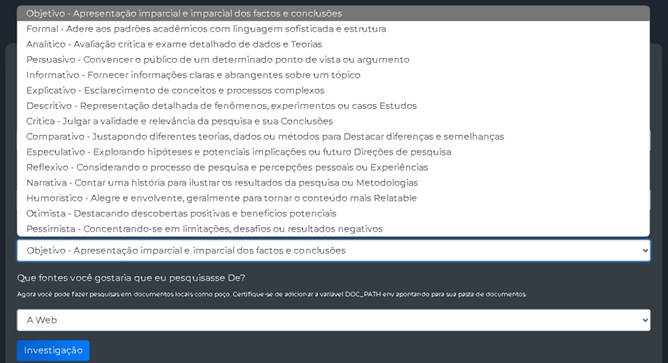
Figura 4: Front-end de interação do GPT Research, com o combobox aberto para definição do tom para o relatório que será gerado, exibindo suas opções.
- “Que fontes você gostaria que eu pesquisasse De?”

Figura 5: Front-end de interação do GPT Research, com o combobox aberto para escolha das fontes que devem ser pesquisadas para geração do resultado, exibindo suas opções.
Após a configuração e acionamento da pesquisa, os resultados são apresentados, organizados em:
- “Agente de Saída”
- Imagens relacionadas;
- “Relatório da Pesquisa”
Além disso, é possível realizar exportação dos resultados, para os formatos abaixo:
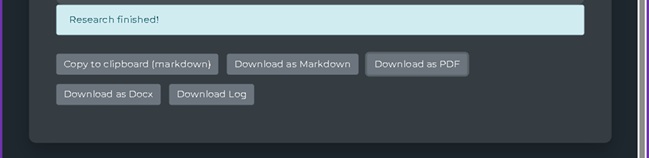
Figura 6: Front-end de interação do GPT Research, com botões para extração e exportação dos resultados.
Já o Smolagents, oferece como primeira opção de interação, o parâmetro ”sentença” ou assunto, o que será o foco de pesquisa.
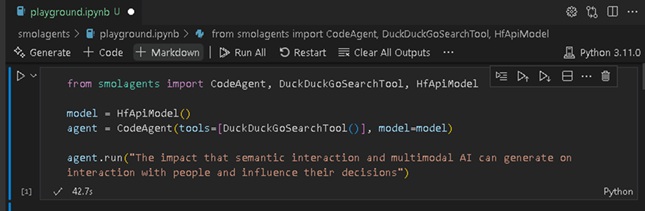
Figura 7: Sessão Jupyter Notebook para interação do Smolagents, utilizando a sentença ou assunto informado.
O processo de pesquisa é organizado e apresentado em 4 passos, sendo:
- Passo 1:
Interpretar e reescrever assunto a ser pesquisado.
- Passo 2:
Definir as URLs dos artigos que queremos ler;
Visitar cada artigo e imprima o conteúdo. - Passo 3:
Sintetizar pontos-chave dos artigos.
- Passo 4:
Resultado final, apresentando link, nome e sumário dos artigos relevantes.

Figura 8: Sessão Jupyter Notebook para interação do Smolagents, apresentado o primeiro passo.
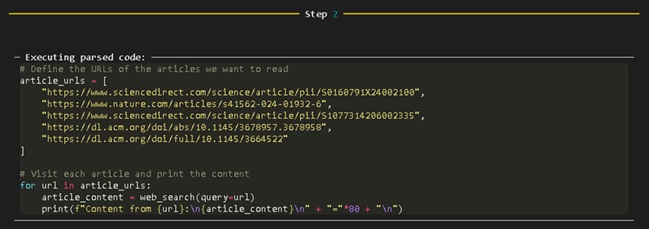
Figura 9: Sessão Jupyter Notebook para interação do Smolagents, apresentado o segundo passo.
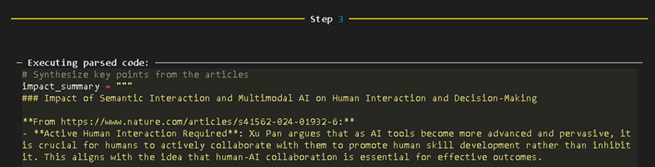
Figura 10: Sessão Jupyter Notebook para interação do Smolagents, apresentado o terceiro passo.

Figura 11: Sessão Jupyter Notebook para interação do Smolagents, apresentado o quarto passo.
As soluções ofereceram pesquisas amplas e mais profundas que uma pesquisa nos motores de busca existentes. Além disso, as organizações e trouxe as referências, o que gera segurança e confiança nos resultados, pois permite verificar a veracidade e estudar melhor os resultados obtidos.
Considerando os resultados acima, posso dizer que a era da informação poderá entrar em um novo momento, iniciando uma nova fase na busca de conhecimento com Sistemas de Pesquisa Abrangente.
Mas e você, o que achou?